![]()
2022年4月27日大约 10 分钟
![]()
衡量算法的优劣,有两种评估方式:事前估计和后期测试。
后期测试有性能测试、基准测试(Benchmark)等手段。
但是,后期测试有以下限制:
所以,需要一种方法,可以不受环境或数据规模的影响,粗略地估计算法的执行效率。这种方法就是复杂度分析。
LSM 树具有以下 3 个特点:
LSM 树的这些特点,使得它相对于 B+ 树,在写入性能上有大幅提升。所以,许多 NoSQL 系统都使用 LSM 树作为检索引擎,而且还对 LSM 树进行了优化以提升检索性能。
B+树是在二叉查找树的基础上进行了改造:树中的节点并不存储数据本身,而是只是作为索引。每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。
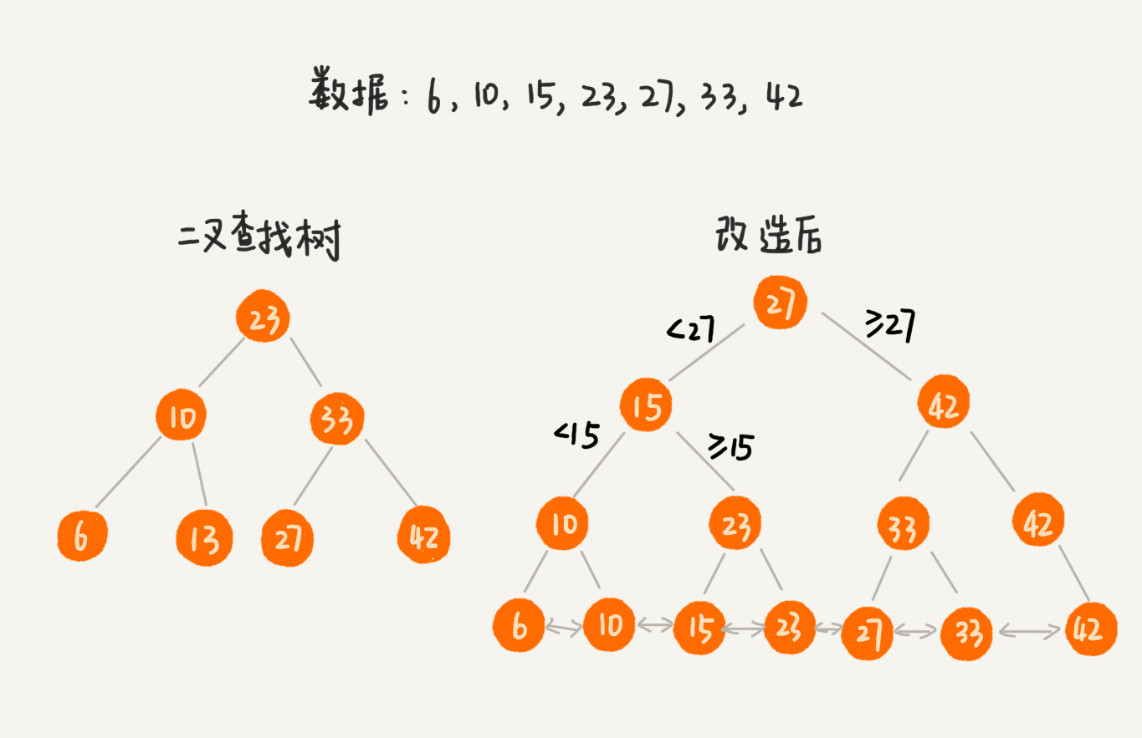
改造之后,如果我们要求某个区间的数据。我们只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的数据,就是符合区间值的所有数据。
Trie 树(又叫“前缀树”或“字典树”)是一种用于快速查询“某个字符串/字符前缀”是否存在的数据结构。
对于一个有序数组,可以使用高效的二分查找法,其时间复杂度为 O(log n)。
但是,即使是有序的链表,也只能使用低效的顺序查找,其时间复杂度为 O(n)。

平衡二叉树的严格定义是这样的:二叉树中任意一个节点的左右子树的高度相差不能大于 1。
完全二叉树、满二叉树其实都是平衡二叉树,但是非完全二叉树也有可能是平衡二叉树。
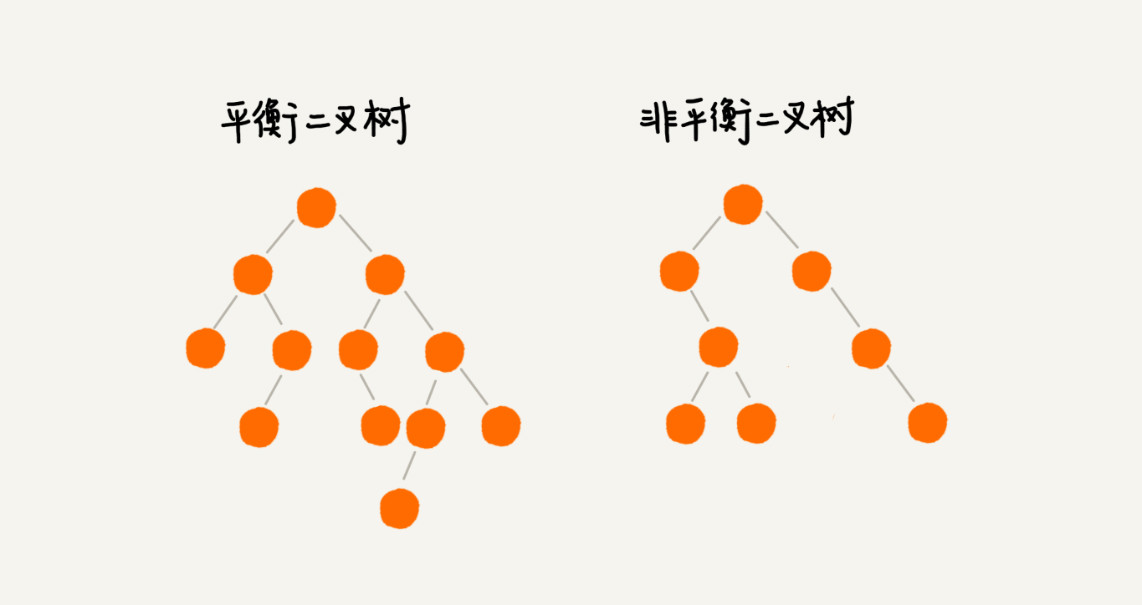
平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。
数组和链表分别代表了连续空间和不连续空间的存储方式,它们是线性表(Linear List)的典型代表。其他所有的数据结构,比如栈、队列、二叉树、B+ 树等,实际上都是这两者的结合和变化。
数组用 连续 的内存空间来存储数据。
数组元素的访问是以行或列索引的单一下标表示。
在计算机科学中,一个图就是一些顶点的集合,这些顶点通过一系列边结对(连接)。顶点用圆圈表示,边就是这些圆圈之间的连线。顶点之间通过边连接。
哈希表 是一种使用 哈希函数 组织数据,以支持快速插入和搜索的数据结构。
有两种不同类型的哈希表:哈希集合 和 哈希映射。
- 哈希集合 是集合数据结构的实现之一,用于存储非重复值。
- 哈希映射 是映射 数据结构的实现之一,用于存储(key, value)键值对。