Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。Table API 是用于 Scala 和 Java 语言的查询 API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。无论输入是连续的(流式)还是有界的(批处理),在两个接口中指定的查询都具有相同的语义,并指定相同的结果。
2022年3月18日大约 4 分钟
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。Table API 是用于 Scala 和 Java 语言的查询 API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。无论输入是连续的(流式)还是有界的(批处理),在两个接口中指定的查询都具有相同的语义,并指定相同的结果。
(1)使用 docker 命令拉取镜像
docker pull flinkApache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
关键概念:源源不断的流式数据处理、事件时间、有状态流处理和状态快照
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
Apache Flink 的一种常见应用场景是 ETL(抽取、转换、加载)管道任务。从一个或多个数据源获取数据,进行一些转换操作和信息补充,将结果存储起来。在这个教程中,我们将介绍如何使用 Flink 的 DataStream API 实现这类应用。
这里注意,Flink 的 Table 和 SQL API 完全可以满足很多 ETL 使用场景。但无论你最终是否直接使用 DataStream API,对这里介绍的基本知识有扎实的理解都是有价值的。
ProcessFunction 将事件处理与 Timer,State 结合在一起,使其成为流处理应用的强大构建模块。 这是使用 Flink 创建事件驱动应用程序的基础。它和 RichFlatMapFunction 十分相似, 但是增加了 Timer。
如果你已经体验了 流式分析训练 的动手实践, 你应该记得,它是采用 TumblingEventTimeWindow 来计算每个小时内每个司机的小费总和, 像下面的示例这样:
Flink 为流式/批式处理应用程序的开发提供了不同级别的抽象。

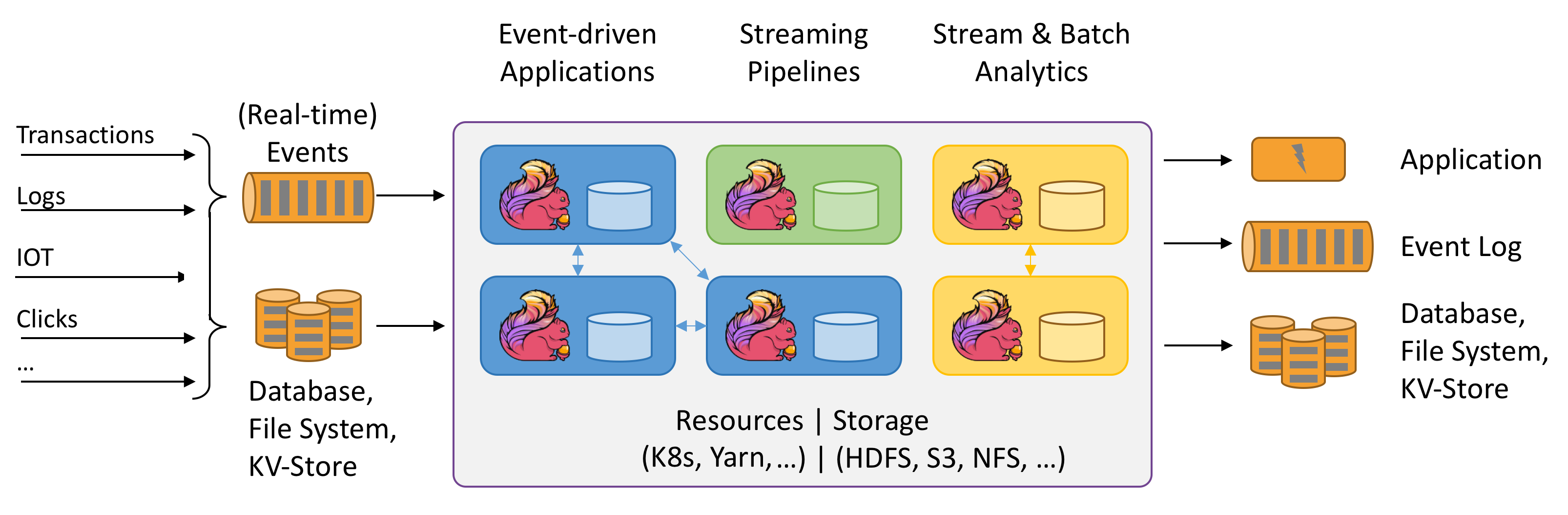
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。